
Technology
JEPA vs LLMs: The Architecture War That Will Define the Next Decade of AI
22 APR2026
10 MINRead
---
Views
Yann LeCun recently validated our technical analysis of VL-JEPA as the definitive “Anti-LLM.” This update reinforces the architecture’s role as a cornerstone for future World Models, incorporating insights into the scalability of non-generative AI.
For the last several years, AI development has been defined by the Autoregressive Era. The dominant paradigm in Vision-Language Models (VLMs) has been autoregressive generation: the simple but powerful idea of predicting the next word in a sequence. Nearly every major VLM, from Flamingo to InstructBLIP, is built on this foundation, taking a visual input and a text query to generate a textual response one token at a time. This common approach has become so ingrained that it’s often treated as the only way to build powerful multimodal systems.
However, this autoregressive approach is both inadequate and computationally expensive. By forcing models to predict the next token, we compel them to waste immense effort modeling task-irrelevant details like word choice, linguistic style, or paraphrasing. Instead of learning the core meaning of an answer, these models must also learn to perfectly reconstruct its surface-level form. This process not only requires larger models and more training data but also introduces unnecessary latency during inference, as the model must complete its token-by-token decoding before the underlying semantics are revealed.
A new paper from Meta FAIR and NYU introduces VL-JEPA, a model that presents a compelling alternative. VL-JEPA is a Joint Embedding Predictive Architecture that sidesteps the token generation game entirely. Instead of generating text, it learns to predict continuous embeddings (abstract numerical representations of text) in a shared semantic space. This fundamental shift—central to the ongoing AI architecture war—allows the model to focus exclusively on task-relevant semantics while gracefully ignoring the noise of surface-level linguistic variability, leading to a far more efficient and direct path to visual understanding.
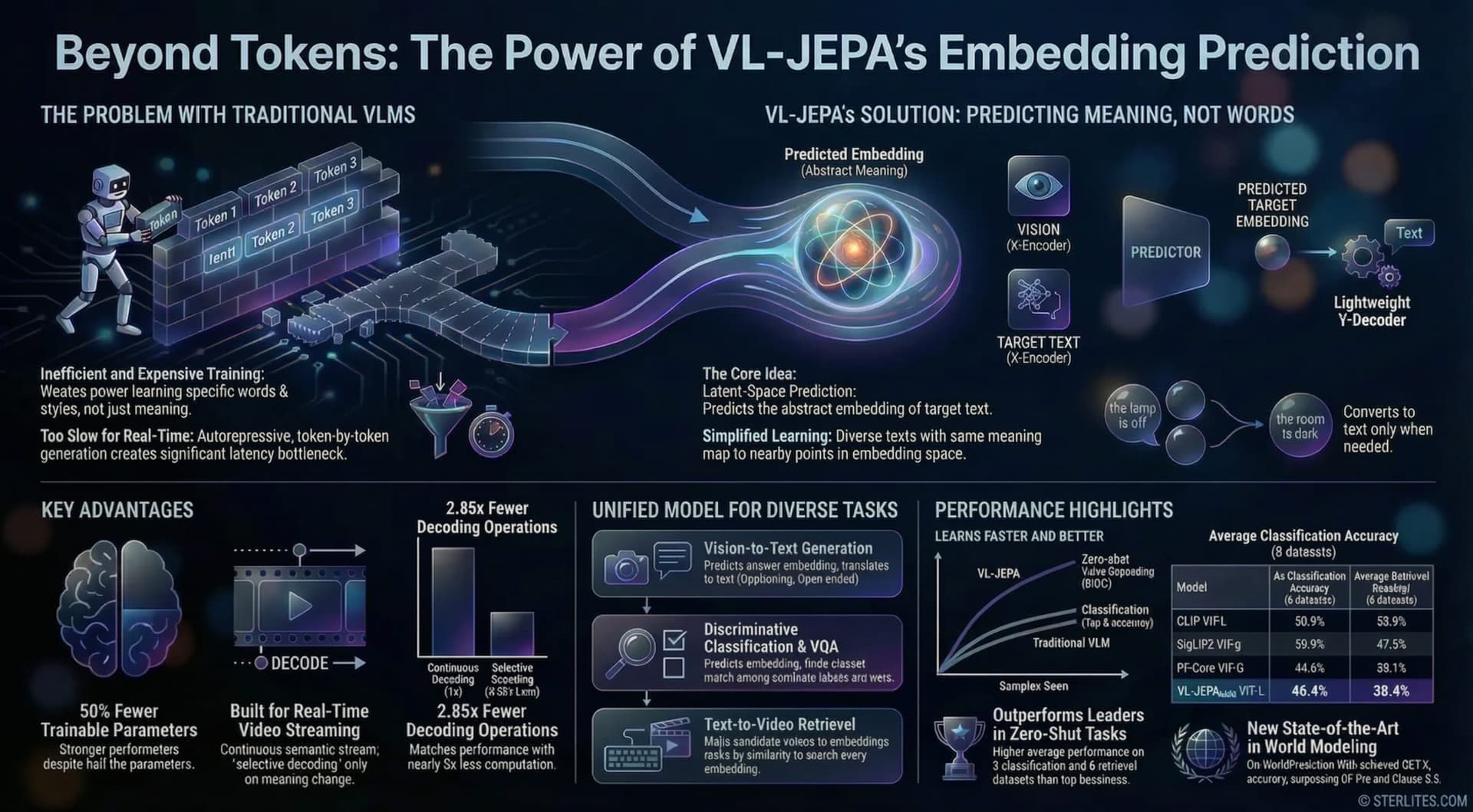
This is the core architectural principle behind VL-JEPA. Instead of generating raw data (like pixels or text tokens), a JEPA model learns by predicting the representation of a target, such as a text answer, from the representation of a context, such as an image and a text query. This encourages the model to learn abstract, high-level features rather than superficial details. In simple terms, instead of forcing the model to predict the exact words in a sentence, JEPA teaches it to predict the idea or meaning behind that sentence.
VL-JEPA’s output is not a sequence of discrete tokens but a continuous vector in an abstract representation space. This is a critical distinction. In the raw token space, two sentences like “the lamp is turned off” and “room will go dark” are completely different sequences. In VL-JEPA’s embedding space, these semantically similar answers are mapped to nearby points, dramatically simplifying the learning task and making the training process more efficient.
Selective Decoding is an inference-time technique that is native to VL-JEPA’s design. Because the model outputs a continuous stream of semantic embeddings, a lightweight text decoder only needs to be activated when a meaningful semantic change is detected, such as when the local variance of the embedding stream exceeds a certain threshold. This stands in stark contrast to standard VLMs, which are forced to perform expensive, token-by-token decoding for any output, making VL-JEPA ideal for real-time video analysis.
The authority of this work is underscored by its list of co-authors, which includes Meta FAIR and NYU’s Yann LeCun. As a Turing Award laureate and vocal proponent of non-generative, predictive architectures, LeCun’s long-held belief that learning world models through prediction in abstract spaces is a more principled path to intelligence has now been physically demonstrated. This analysis was recently validated by LeCun himself, cementing VL-JEPA’s status as the definitive “Anti-LLM.”
A key indicator of VL-JEPA’s efficiency is its size. The supervised fine-tuned model, VL-JEPASFT, achieves performance comparable to much larger, established VLMs on difficult Visual Question Answering (VQA) benchmarks, all with only 1.6 billion parameters.
VL-JEPA’s non-autoregressive design makes it uniquely suited for real-world scenarios where low latency is critical, such as robotics and edge intelligence. These applications require AI systems that can provide a real-time response, a task for which traditional token-by-token generation is often too slow and computationally demanding.
The model’s core efficiency advantage comes from Selective Decoding. The research demonstrates that this technique “reduces the number of decoding operations by ~2.85x while maintaining similar performance” when compared to a non-adaptive, uniform decoding strategy. This isn’t a minor optimization; it’s a fundamental change in how a model interacts with a continuous stream of information.
This efficiency gain is particularly transformative for online video streaming applications. A system built on VL-JEPA can maintain always-on semantic monitoring by processing the lightweight embedding stream in real time. It can then trigger the more expensive text decoder only when a new event occurs or a meaningful change is detected, avoiding the high computational cost of continuous, unnecessary text generation.
The paper provides strong empirical evidence to back its architectural claims, demonstrating state-of-the-art performance in key areas.
The success of VL-JEPA is a powerful declaration that the AI community’s obsession with ever-larger generative models has been a brute-force distraction. For years, the field has pursued intelligence by scaling up autoregressive prediction, a path that this research proves is not only inefficient but fundamentally misguided. VL-JEPA’s success may signal the end of the Autoregressive Era’s dominance and the beginning of a new focus on efficient, predictive world models.
By learning to predict in a simplified, continuous semantic space rather than a complex, discrete token space, models can discard irrelevant noise and focus on what truly matters: meaning. This work proves that a more elegant and robust path forward lies in better representation learning, even if it requires solving the JEPA collapse problem. The industry has been chasing perfect grammar, but VL-JEPA proves the real prize has always been a perfect understanding of the world.
Thinking about AI & Technology? Our team has helped 100+ companies turn AI insight into production reality.
Book a highly tactical 30-minute strategy session. We apply the engineering rigor developed with McKinsey, DHL, and Walmart to accelerate AI for startups and enterprises alike. Let's bypass the hype, evaluate your specific use case, and map a concrete path to production.
Establish your authority. Amplify these insights with your professional network.
Hand-picked insights to expand your understanding of the evolving AI landscape.


